Introduction #
I’m working on SVG filter effects in librsvg, a GNOME library for rendering SVG files to Cairo surfaces. After finishing porting all filters from C to Rust and adding tests, I started investigating the filter performance. With the codebase converted to Rust, I am able to confidently apply important optimizations such as parallelization. In this post I’ll show how I parallelized two computation-intensive filter primitives.
Rayon #
Rayon is a Rust crate for introducing parallelism into existing code. It utilizes Rust’s type system to guarantee memory safety and data-race free execution. Rayon mimics the standard Rust iterators, so it’s possible to convert the existing iterator-using code with next to no changes. Compare the following single-threaded and parallel code:
// Single-threaded.
fn sum_of_squares(input: &[i32]) -> i32 {
input.iter()
.map(|i| i * i)
.sum()
}
// Parallelized with rayon.
use rayon::prelude::*;
fn sum_of_squares(input: &[i32]) -> i32 {
input.par_iter()
.map(|i| i * i)
.sum()
}
By merely using .par_iter() instead of .iter(), the computation becomes parallelized.
Parallelizing Lighting Filters #
Going forward with analyzing and improving the performance of the infamous mobile phone case, the two biggest time sinks were the lighting and the Gaussian blur filter primitives. It can be easily seen on the callgrind graph from KCachegrind:
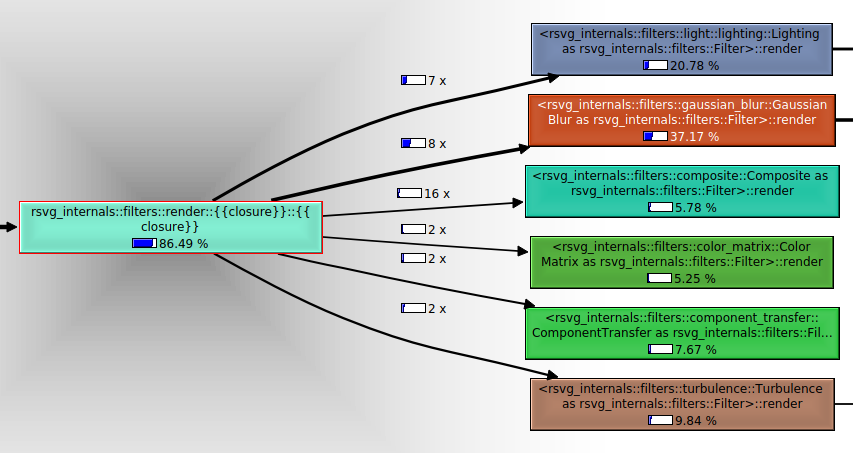
Since I was working on optimizing the lighting filters, I decided to try out parallelization there first. The lighting filter primitives in SVG (feDiffuseLighting and feSpecularLighting) can be used to cast light onto the canvas using a render of an existing SVG node as a bump map. The computation is quite involved, but it boils down to performing a number of arithmetic operations for each pixel of the input surface independently of the others—a perfect target for parallelization. This is what the code initially looked like:
let mut output_surface = ImageSurface::create(
cairo::Format::ARgb32,
input_surface.width(),
input_surface.height(),
)?;
let output_stride = output_surface.get_stride() as usize;
let mut output_data = output_surface.get_data().unwrap();
let mut compute_output_pixel = |x, y, normal: Normal| {
let output_pixel = /* expensive computations */;
output_data.set_pixel(output_stride, output_pixel, x, y);
};
// Compute the edge pixels
// <...>
// Compute the interior pixels
for y in bounds.y0 as u32 + 1..bounds.y1 as u32 - 1 {
for x in bounds.x0 as u32 + 1..bounds.x1 as u32 - 1 {
compute_output_pixel(
x,
y,
interior_normal(&input_surface, bounds, x, y),
);
}
}
The edge pixel computation is separated out for optimization reasons and it’s not important. We want to focus on the main loop over the interior pixels: it takes up the most time. What we’d like to do is to take the outer loop over the image rows and run it in parallel on a thread pool. Since each row (well, each pixel in this case) is computed independently of the others, we should be able to do it without much hassle. However, we cannot do it right away: the compute_output_pixel closure mutably borrows output_data, so sharing it over multiple threads would mean multiple threads get concurrent mutable access to all image pixels, which could result in a data race and so won’t pass the borrow checker of the Rust compiler. Instead, we can split the output_data slice into row-sized non-overlapping chunks and feed each thread only those chunks that it needs to process. This way no thread can access the data of another thread. Let’s change the closure to accept the target slice (as opposed to borrowing it from the enclosing scope). Since the slices will start from the beginning of each row rather than the beginning of the whole image, we’ll also add an additional base_y argument to correct the offsets.
let compute_output_pixel =
|mut output_slice: &mut [u8],
base_y,
x,
y,
normal: Normal| {
let output_pixel = /* expensive computations */;
output_slice.set_pixel(
output_stride,
output_pixel,
x,
y - base_y,
);
};
// Compute the interior pixels
for y in bounds.y0 as u32 + 1..bounds.y1 as u32 - 1 {
for x in bounds.x0 as u32 + 1..bounds.x1 as u32 - 1 {
compute_output_pixel(
output_data,
0,
x,
y,
interior_normal(&input_surface, bounds, x, y),
);
}
}
Now we can convert the outer loop to operate through iterators using the chunks_mut() method of a slice which does exactly what we want: returns the slice in evenly sized non-overlapping mutable chunks.
let compute_output_pixel =
|mut output_slice: &mut [u8],
base_y,
x,
y,
normal: Normal| {
let output_pixel = /* expensive computations */;
output_slice.set_pixel(
output_stride,
output_pixel,
x,
y - base_y,
);
};
// Compute the interior pixels
let first_row = bounds.y0 as u32 + 1;
let one_past_last_row = bounds.y1 as u32 - 1;
let first_pixel = (first_row as usize) * output_stride;
let one_past_last_pixel =
(one_past_last_row as usize) * output_stride;
output_data[first_pixel..one_past_last_pixel]
.chunks_mut(output_stride)
.zip(first_row..one_past_last_row)
.for_each(|(slice, y)| {
for x in bounds.x0 as u32 + 1..bounds.x1 as u32 - 1 {
compute_output_pixel(
slice,
y,
x,
y,
interior_normal(
&input_surface,
bounds,
x,
y,
),
);
}
});
And finally, parallelize by simply changing chunks_mut() to par_chunks_mut():
use rayon::prelude::*;
output_data[first_pixel..one_past_last_pixel]
.par_chunks_mut(output_stride)
.zip(first_row..one_past_last_row)
.for_each(|(slice, y)| {
for x in bounds.x0 as u32 + 1..bounds.x1 as u32 - 1 {
compute_output_pixel(
slice,
y,
x,
y,
interior_normal(
&input_surface,
bounds,
x,
y,
),
);
}
});
Let’s see if the parallelization worked! Here I’m using time to measure how long it takes to render the mobile phone SVG. Before parallelization:
└─ time ./rsvg-convert -o temp.png mobile_phone_01.svg
6.95user 0.66system **0:07.62**elapsed **99%**CPU (0avgtext+0avgdata 270904maxresident)k
0inputs+2432outputs (0major+714373minor)pagefaults 0swaps
After parallelization:
└─ time ./rsvg-convert -o temp.png mobile_phone_01.svg
7.47user 0.63system **0:06.04**elapsed **134%**CPU (0avgtext+0avgdata 271328maxresident)k
0inputs+2432outputs (0major+714460minor)pagefaults 0swaps
Note that even though the user time went up, the elapsed time went down by 1.5 seconds, and the CPU utilization increased past 100%. Success!
Parallelizing Gaussian Blur #
Next, I set out to parallelize Gaussian blur, the biggest timesink for the phone and arguably one of the most used SVG filters altogether. The SVG specification hints that for all reasonable values of the standard deviation parameter the blur can be implemented as three box blurs (taking the average value of the pixels) instead of the much more costly Gaussian kernel convolution. Pretty much every SVG rendering agent implements it this way since it’s much faster and librsvg is no exception. This is why you’ll see functions called box_blur and not gaussian_blur. Both box blur and Gaussian blur are separable convolutions, which means it’s possible to implement them as two passes, one of which is a loop blurring each row of the image and another is a loop blurring each column of the image independently of the others. For box blur specifically it allows for a much more optimized convolution implementation. In librsvg, the box blur function contains an outer loop over the rows or the columns of the input image, depending on the vertical argument and an inner loop over the columns or the rows, respectively. It uses i and j for the outer and inner loop indices and has some helper functions to convert those to the actual coordinates, depending on the direction.
// Helper functions for getting and setting the pixels.
let pixel = |i, j| {
let (x, y) = if vertical { (i, j) } else { (j, i) };
input_surface.get_pixel_or_transparent(bounds, x, y)
};
let mut set_pixel = |i, j, pixel| {
let (x, y) = if vertical { (i, j) } else { (j, i) };
output_data.set_pixel(output_stride, pixel, x, y);
};
// Main loop
for i in other_axis_min..other_axis_max {
// Processing the first pixel
// <...>
// Inner loop
for j in main_axis_min + 1..main_axis_max {
// <...>
}
}
Trying to convert this code to use chunks_mut() just like the lighting filters, we stumble on an issue: if the outer loop is iterating over columns, rather than rows, the output slices for all individual columns overlap (because the pixels are stored in row-major order). We need some abstraction, like a matrix slice, that can be split into non-overlapping mutable subslices by rows or by columns. The first thing that comes to mind is to try using the Matrix type from the nalgebra crate which does have that functionality. However, it turns out that nalgebra doesn’t currently support rayon or even have by-row or by-column iterators. I tried implementing my own iterators but that required some very non-obvious unsafe code with odd trait bound restrictions which I really wasn’t sure were correct. Thus, I scrapped that code and made my own wrapper for the ImageSurface which only contains things needed for this particular use case. To reiterate, we need a wrapper that:
- provides write access to the image pixels,
- can be split by row or by column into non-overlapping chunks,
- is
Send, i.e. can be safely sent between threads (for parallelizing).
Here’s what I came up with:
struct UnsafeSendPixelData<'a> {
width: u32,
height: u32,
stride: isize,
ptr: NonNull<u8>,
_marker: PhantomData<&'a mut ()>,
}
unsafe impl<'a> Send for UnsafeSendPixelData<'a> {}
impl<'a> UnsafeSendPixelData<'a> {
/// Creates a new `UnsafeSendPixelData`.
///
/// # Safety
/// You must call `cairo_surface_mark_dirty()` on the
/// surface once all instances of `UnsafeSendPixelData`
/// are dropped to make sure the pixel changes are
/// committed to Cairo.
#[inline]
unsafe fn new(
surface: &mut cairo::ImageSurface,
) -> Self {
assert_eq!(
surface.get_format(),
cairo::Format::ARgb32
);
let ptr = surface.get_data().unwrap().as_mut_ptr();
Self {
width: surface.get_width() as u32,
height: surface.get_height() as u32,
stride: surface.get_stride() as isize,
ptr: NonNull::new(ptr).unwrap(),
_marker: PhantomData,
}
}
/// Sets a pixel value at the given coordinates.
#[inline]
fn set_pixel(&mut self, pixel: Pixel, x: u32, y: u32) {
assert!(x < self.width);
assert!(y < self.height);
let value = pixel.to_u32();
unsafe {
let ptr = self.ptr.as_ptr().offset(
y as isize * self.stride + x as isize * 4,
) as *mut u32;
*ptr = value;
}
}
/// Splits this `UnsafeSendPixelData` into two at the
/// given row.
///
/// The first one contains rows `0..index` (index not
/// included) and the second one contains rows
/// `index..height`.
#[inline]
fn split_at_row(self, index: u32) -> (Self, Self) {
assert!(index <= self.height);
(
UnsafeSendPixelData {
width: self.width,
height: index,
stride: self.stride,
ptr: self.ptr,
_marker: PhantomData,
},
UnsafeSendPixelData {
width: self.width,
height: self.height - index,
stride: self.stride,
ptr: NonNull::new(unsafe {
self.ptr
.as_ptr()
.offset(index as isize * self.stride)
}).unwrap(),
_marker: PhantomData,
},
)
}
/// Splits this `UnsafeSendPixelData` into two at the
/// given column.
///
/// The first one contains columns `0..index` (index not
/// included) and the second one contains columns
/// `index..width`.
#[inline]
fn split_at_column(self, index: u32) -> (Self, Self) {
assert!(index <= self.width);
(
UnsafeSendPixelData {
width: index,
height: self.height,
stride: self.stride,
ptr: self.ptr,
_marker: PhantomData,
},
UnsafeSendPixelData {
width: self.width - index,
height: self.height,
stride: self.stride,
ptr: NonNull::new(unsafe {
self.ptr
.as_ptr()
.offset(index as isize * 4)
}).unwrap(),
_marker: PhantomData,
},
)
}
}
The wrapper contains a pointer to the data rather than a mutable slice of the data, so the intermediate pixels (which cannot be accessed through set_pixel()) are not mutably aliased between different instances of UnsafeSendPixelData. Now it’s possible to implement an iterator over the rows or the columns for this wrapper, however I went with a different, simpler approach: using rayon’s scope functionality which allows spawning worker threads directly into rayon’s thread pool. First, let’s change the existing code to operate on individual rows or columns, just like we did with the lighting filters:
// The following loop assumes the first row or column of
// `output_data` is the first row or column inside `bounds`.
let mut output_data = if vertical {
output_data.split_at_column(bounds.x0 as u32).1
} else {
output_data.split_at_row(bounds.y0 as u32).1
};
for i in other_axis_min..other_axis_max {
// Split off one row or column and launch its processing
// on another thread. Thanks to the initial split before
// the loop, there's no special case for the very first
// split.
let (mut current, remaining) = if vertical {
output_data.split_at_column(1)
} else {
output_data.split_at_row(1)
};
output_data = remaining;
// Helper function for setting the pixels.
let mut set_pixel = |j, pixel| {
// We're processing rows or columns one-by-one, so
// the other coordinate is always 0.
let (x, y) = if vertical { (0, j) } else { (j, 0) };
current.set_pixel(pixel, x, y);
};
// Processing the first pixel
// <...>
// Inner loop
for j in main_axis_min + 1..main_axis_max {
// <...>
}
}
I could avoid the current and the base_i arguments to the set_pixel closure because I can declare the closure from within the loop, whereas in the lighting filters code the compute_output_pixel closure had to be used and so declared outside of the main loop. Now it’s a simple change to split the work across rayon’s threads:
// The following loop assumes the first row or column of
// `output_data` is the first row or column inside `bounds`.
let mut output_data = if vertical {
output_data.split_at_column(bounds.x0 as u32).1
} else {
output_data.split_at_row(bounds.y0 as u32).1
};
// Establish a scope for the threads.
rayon::scope(|s| {
for i in other_axis_min..other_axis_max {
// Split off one row or column and launch its
// processing on another thread. Thanks to the
// initial split before the loop, there's no special
// case for the very first split.
let (mut current, remaining) = if vertical {
output_data.split_at_column(1)
} else {
output_data.split_at_row(1)
};
output_data = remaining;
// Spawn the thread for this row or column.
s.spawn(move |_| {
// Helper function for setting the pixels.
let mut set_pixel = |j, pixel| {
// We're processing rows or columns
// one-by-one, so the other coordinate is
// always 0.
let (x, y) =
if vertical { (0, j) } else { (j, 0) };
current.set_pixel(pixel, x, y);
};
// Processing the first pixel
// <...>
// Inner loop
for j in main_axis_min + 1..main_axis_max {
// <...>
}
});
}
});
Let’s measure the performance. In the end of the previous section we had:
└─ time ./rsvg-convert -o temp.png mobile_phone_01.svg
7.47user 0.63system **0:06.04**elapsed **134%**CPU (0avgtext+0avgdata 271328maxresident)k
0inputs+2432outputs (0major+714460minor)pagefaults 0swaps
And now after the parallelization:
└─ time ./rsvg-convert -o temp.png mobile_phone_01.svg
10.32user 1.10system **0:04.57**elapsed **250%**CPU (0avgtext+0avgdata 272588maxresident)k
0inputs+2432outputs (0major+1009498minor)pagefaults 0swaps
We cut another 1.5 seconds and further increased the CPU utilization!
Conclusion #
Rayon is an excellent crate which provides a multitude of ways for safely parallelizing Rust code. It builds on idiomatic concepts such as iterators, but also contains a number of other convenient ways for parallelizing code when standard iterators aren’t sufficient or wouldn’t be very convenient. It uses the Rust’s type system to statically guarantee the absence of data races and manages the low-level details on its own allowing the programmer to focus on the actual computation. The parallelized filters are now included in the latest development release of librsvg for testing if using multiple threads leads to any issues downstream.